常用加密&编码
- 加密与编码是 Web 应用在传输数据时常用的技术之一,有以下四种常见场景:
- 存储密码加密
- Web & 数据库 & 系统
- 传输数据编码
- 数据传输一致性
- 代码特性加密
- JS 代码混淆
- 数据显示编码
- 字符
- 字符集
- 字符编码
- 存储密码加密
存储密码加密
- 作为互联网公司的信息安全从业人员经常要处理撞库扫号事件,产生撞库扫号的根本原因是:一些企业发生了信息泄露事件,且这些泄露数据未加密或者加密方式比较弱,导致黑客可以还原出原始的用户密码。
- 要完全防止信息泄露是非常困难的事情,除了防止黑客外,还要防止内部人员泄密。
- 但如果采用合适的算法去加密用户密码,即使信息泄露出去,黑客也无法还原出原始的密码(或者还原的代价非常大)。
- 常见的数据加密算法有:
- MD5
- SHA
- NTLM
- AES
- DES
- RC4
哈希算法
- 哈希算法(Hash Algorithm)是一种将任意长度的数据映射为固定长度哈希值的算法。
- 它主要通过执行一系列数学运算和逻辑操作来生成哈希值,该哈希值通常用于数据完整性验证、身份验证、密码存储和查找等应用。
- 哈希算法的主要特点:
- 唯一性:对于不同的输入数据,哈希算法应该生成不同的哈希值。理想情况下,每个输入都应该有唯一的哈希值,避免碰撞(即不同的输入产生相同的哈希值)的发生。然而,由于哈希值的固定长度限制,完全避免碰撞是不可能的。
- 固定长度输出:无论输入数据的大小,哈希算法始终生成固定长度的哈希值。常见的哈希算法,如 MD5(128位)、SHA-256(256位)等,都有固定的输出长度。这使得哈希算法适用于存储和比较哈希值的场景。
- 不可逆性:哈希算法是单向的,即从哈希值推导出原始输入数据是非常困难的。理想情况下,对于给定的哈希值,无法从中还原出原始数据。这种特性使得哈希算法在密码存储中非常有用,因为即使哈希值被泄露,攻击者也难以还原出原始密码。
- 敏感性:哈希算法对输入数据的任何微小变化都应该产生不同的哈希值。即使输入的数据只有一位的变化,哈希值也应该有较大的差异。这种特性使得哈希算法对数据的修改具有很强的敏感性,可用于验证数据的完整性。
- 高效性:好的哈希算法应该具有高效的计算性能。它应该能够在合理的时间内处理大量的数据,并生成相应的哈希值。高效的哈希算法可以在实际应用中提供快速的数据处理和验证。
MD5
- MD5(Message Digest Algorithm 5)是一种哈希函数,用于将任意长度的数据转换为固定长度的哈希值(通常为 128 位)。
- MD5 广泛用于校验数据完整性和验证密码等场景。然而,由于 MD5 存在一些安全性问题,如:碰撞攻击(在不同的输入上生成相同的哈希值),因此不再推荐用于安全性要求较高的应用。
- 优点:计算速度快,生成的哈希值长度较短。
- 缺点:安全性较低,易受到碰撞攻击。
SHA
- SHA(Secure Hash Algorithm)是一系列哈希函数家族,如:SHA-1、SHA-256、SHA-512 等。
- SHA-1 也被广泛使用,但也存在安全性问题,因此逐渐被淘汰。
- SHA-256 和 SHA-512 等较新的版本提供更高的安全性。
- SHA 家族的哈希函数通常用于校验文件完整性、数字签名和密码存储等领域。
- 优点:生成的哈希值长度较长,安全性较高。
- 缺点:计算速度较慢。
传输数据编码
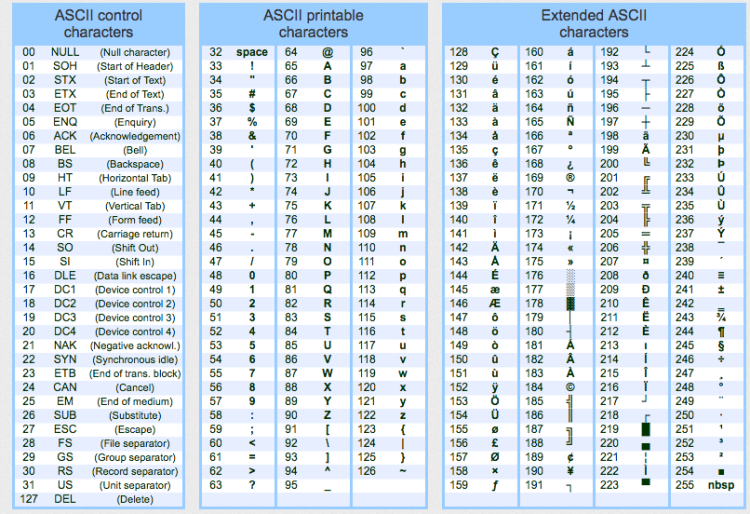
- 在计算机中任何数据都是按 ASCII 码存储的,而 ASCII 码的 128~255 之间的值是不可见字符。
- 而在网络上交换数据时,比如说从 A 地传到 B 地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于数据传输的。
- 所以在数据传输的过程中,我们往往需要对一些内容进行编码,来保证传输数据的可读性。
ASCII
- ASCII(American Standard Code for Information Interchange)是一种字符编码标准,使用 7 位二进制数表示 128 个字符,包括英文字母、数字和常用符号。
- 每个字符都有一个唯一的 ASCII 码值,ASCII 编码常用于计算机系统和通信中,它使得计算机能够处理和显示文本数据。
Base64
- Base64 编码是一种将二进制数据转换为可打印字符的编码方式。
- 它使用 64 个字符(A-Z、a-z、0-9 和两个额外字符)来表示 6 位二进制数,每 3 个字节的数据转换为 4 个 Base64 字符。
- Base64 编码常用于在文本环境中传输或存储二进制数据,例如:电子邮件中传输二进制附件。
URL
- URL 编码(也称为百分号编码或 URL 转义)是一种用于在 URL 中表示特殊字符和非 ASCII 字符的编码方式。
- UR L编码使用 % 加上两个十六进制数字表示一个字符的 ASCII 码值。它主要用于确保 URL 中的特殊字符不会干扰 URL 的结构和解析。
Hex
- Hex(十六进制)编码是一种将二进制数据转换为十六进制表示的编码方式。
- 它使用 0-9 和 A-F 这 16 个字符来表示 4 位二进制数。
- 每个字节转换为两个十六进制数字,因此十六进制编码通常是二进制数据的两倍大小。
- Hex 编码常用于调试和表示二进制数据。
代码特性加密
- 现在做软件开发的公司对于源代码保护越来越重视了,由于源代码一般都牵扯到公司的核心竞争力,可以说企业能不能在同行中展露头角,具备核心竞争力,源码的保护起到了决定性的作用。
- 除了后端代码,像是前端的 JavaScript 也是需要进行加密的。
- 因为有的时候 JS 代码可能会泄露网站的一些特殊路径,或者说一些静态的秘钥信息。
- 前端 JS 代码的保护,必需要混淆和加密共用,单独的 JS 源代码加密,是行不通的,更不可能有所谓的 JS 不可逆加密。
- 因为代码在浏览器端执行时,必须转解密还原成原始代码,才能被浏览器的 JS 引擎识别和运行。
- 在解密后,会存在完整的原始 JS 代码,这是非常不安全的存在,有多种方法可将原始的 JS 代码显示出来。
- 常见的 JS 代码混淆方式有:
- 字符搜索和串替换
- 随机插入伪僵尸代码
- 字符串十六进制化
数据显示编码
字符
- 字符是指书写系统中的基本单位,可以是字母、数字、标点符号、符号、空格或其他可打印或不可打印的符号。字符是人类语言中表达意义的基本元素,例如英文字母、汉字等。
- 在计算机中,字符通常使用特定的编码表示。
字符集
- 字符集是一组字符的集合。它定义了一种语言或一组语言所使用的所有字符。
- 常见的字符集包括 ASCII、Unicode 和各种语言特定的字符集(如 GBK、UTF-8 等)。
- 字符集可以涵盖单个语言或多种语言,并且可以包含字母、数字、标点符号、符号等。
- 不同的字符集支持不同的字符范围和特殊符号。
字符编码
- 字符编码是将字符映射到计算机内部表示的规则或方案。
- 它将字符集中的字符转换为计算机可以理解和处理的二进制形式。
- 字符编码使用不同的编码方案来分配唯一的数字值给每个字符。
- 常见的字符编码方案包括 ASCII、UTF-8、UTF-16 等。
- 不同的字符编码方案使用不同的位数来表示字符,可以是 8 位、16 位或更多。
GB2312
- GB2312 是中华人民共和国国家标准局发布的汉字字符集和编码方案。
- 它是早期的中文字符编码标准,包含了约 7,000 个常用的简体汉字和符号。
- GB2312 编码使用 16 位(2个字节)表示每个字符,提供了对中文字符的支持。
- GB2312 编码主要用于中国大陆早期的计算机系统和操作系统,现在已被 GBK 和 Unicode 编码取代。
GBK
- GBK(GuoBiaoKuozhan)是中华人民共和国国家标准局发布的汉字字符集和编码方案。
- 它是 GB2312 标准的扩展版本,支持更多的汉字字符。
- GBK 字符集包含了约 21,000 个中文汉字和数字符号,同时还包括了其他语言字符。
- GBK 编码使用 16 位(2个字节)表示每个字符,提供对中文字符的良好支持。
- GBK 编码在中国大陆广泛使用,但随着 Unicode 编码的普及,GBK 逐渐被取代。
GB18030
- GB18030 是中华人民共和国国家标准局发布的字符集和编码方案,是 GB2312 和 GBK 的升级版本。
- 它是为了满足中文字符集的扩展需求和国际化支持而设计的。
- GB18030 字符集包含了汉字、拉丁字母、数字、标点符号和其他特殊字符等。
- 它支持约 27,533 个汉字(包括简体和繁体)、数十种语言的字符以及特殊符号。
- GB18030 字符集还包含了 Unicode 标准中的字符。
- GB18030 编码使用变长编码方案,可以使用 1 个、2 个或 4 个字节来表示一个字符。
- 对于 ASCII 字符,使用 1 个字节表示,与 ISO-8859-1 编码兼容。
- 对于 GB2312 字符集中的字符,使用 2 个字节表示,与 GBK 编码兼容。
- 对于 GB18030 字符集中的其他字符,使用 4 个字节表示。
- GB18030 编码方案在中国大陆广泛应用于计算机系统、操作系统、数据库和应用程序。
- 它提供了对中文字符的完整支持,并能够处理多种语言和特殊字符。
- 由于 GB18030 编码兼容 GB2312 和 GBK,因此旧有使用这两种编码方案的系统和应用程序可以无缝迁移和升级到 GB18030。
BIG5
- BIG5 是繁体中文字符集和编码方案,主要用于台湾和香港地区。
- BIG5 字符集包含了约 13,000 个繁体汉字和符号。
- BIG5 编码使用16位(2个字节)表示每个字符,提供了对繁体中文字符的支持。
- BIG5 编码在台湾和香港地区广泛使用,但在国际化和跨平台应用中受到限制,因为它只适用于繁体中文。
编码问题
计算机是一个电子产品, 它内部其实是用通电和不通电来记录数据的。通电和不通电一共就两种状态,也就是只能描述 0 和 1。
那么问题来了:数字还好,转化成 2 进制就可以了,文字怎么办?
- 聪明的科学家就把文字按照一个固定的顺序编排成数字,以后看见这个数字就表示相对应的文字。
- 反过来,我们看到的文字,对应存储在计算机中就是一串数字,这个过程被称为编码。
早期,计算机是美国发明的,普及率不高, 一般只是在美国使用。
所以,最早的编码结构就是按照美国人的习惯来编码的。对应数字、字母、特殊字符一共也没多少,就形成了最早的编码 ASCII 码。
随着计算机的发展以及普及率的提高,流行到欧洲和亚洲。这时 ASCII 码就不合适了,比如:中文汉字有几万个,而 ASCII 最多也就 256 个位置。
所以 ASCII 不行了,怎么办呢?
这时,不同的国家就提出了不同的编码用来适用于各自的语言环境。
比如:中国的 GBK,GB2312,BIG5,ISO-8859-1 等等,这样各个国家都可以使用计算机了。
GBK:国标码占用 2 个字节,对应 ASCII 码 GBK 直接兼容,这是因为计算机底层是用英文写的,你不支持英文肯定不行。而英文已经使用了 ASCII 码,所以 GBK 要兼容 ASCII。
这里 GBK 前面的 ASCII 码部分,由于使用两个字节,所以对于 ASCII 码而言前几位都是 0。
1 | 字母A:0100 0001 # ASCII 1KB |
- GBK 的弊端:只能中国用,到了非英语、汉语国家就垮了。
- 所以 GBK 不满足我们的使用,这时提出了一个万国码 - Unicode。
- Unicode - 开始设计是每个字符两个字节,设计完了发现我大中国汉字依然无法进行编码。最后只能进行扩充,扩充成 32 位也就是 4 个字节。
- 这回够了,但是问题来了中国字 9 万多,而 unicode 可以表示 41 亿多的文字,根本用不了那么多,太浪费了。
- 于是乎,就提出了新的 UTF 编码,可变长度编码叫 UTF,我们用的最多的就是UTF-8。
1 | GBK:每个字符占 2 个字节,16 位 |
- 单位转换:
1 | 8bit = 1byte |
- 结论:
- ASCII:8bit,主要存放的是英文,数字,特殊符号。
- GBK:16bit, 主要存放中文和亚洲字符. 兼容ascii
- Unicode:16bit、32bit 两个版本,平时我们用的是 16bit 这个版本,存放着全世界所有国家的文字信息,浪费空间(传输和存储)。
- UTF-8:可变长度 Unicode,一般数据传输和存储的时候使用。
- 以上所有编码必须兼容 ASCII。
.png)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yongz丶!






